

終於要進入第二種 Index 了!認識完 B-Tree 之後,我們要來看看 GIN Index。目前 PostgreSQL 可以支援儲存 jsonb 格式的資料,因此有時候會遇到欄位是 jsonb 格式的值,需要搜尋 key value pair 或是用特定的 key 尋找 value。假如遇到類似的狀況,我們可以使用 GIN Index 加快 jsonb 的搜尋速度,今天這篇我們就來實驗一下要怎麼使用。
product_items table:CREATE TABLE product_items (
id SERIAL PRIMARY KEY,
product_data jsonb
);
product_data 是 jsonimport psycopg2
from faker import Faker
import json
import random
fake = Faker()
conn = psycopg2.connect(dbname="", user="", password="")
cur = conn.cursor()
categories = {
"Electronics": {
"colors": ["black", "white", "silver", "gray"],
"prefixes": ["Wireless", "Smart", "Digital", "Premium", "Ultra"],
"items": ["Mouse", "Keyboard", "Headphones", "Charger", "Speaker"],
},
"Furniture": {
"colors": ["brown", "black", "white", "beige", "gray"],
"prefixes": ["Modern", "Classic", "Luxury", "Ergonomic", "Vintage"],
"items": ["Chair", "Table", "Desk", "Shelf", "Cabinet"],
},
"Clothing": {
"colors": ["blue", "black", "red", "white", "green"],
"prefixes": ["Casual", "Premium", "Classic", "Modern", "Stylish"],
"items": ["T-shirt", "Jeans", "Jacket", "Sweater", "Shirt"],
},
}
def generate_product_data(index):
category = fake.random_element(elements=tuple(categories.keys()))
cat_data = categories[category]
name = f"{random.choice(cat_data['prefixes'])} {random.choice(cat_data['items'])}"
color = random.choice(cat_data["colors"])
product_data = {
"product_id": index,
"name": name,
"description": fake.sentence(),
"price": round(random.uniform(9.99, 999.99), 2),
"stock": random.randint(0, 200),
"attributes": {
"color": color,
"weight": f"{random.randint(50, 2000)}g",
"dimensions": f"{random.randint(1, 20)} x {random.randint(1, 20)} x {random.randint(1, 20)} inches",
},
"reviews": [
{
"reviewer": fake.name(),
"rating": random.randint(1, 5),
"comment": fake.sentence(),
}
for _ in range(random.randint(0, 5))
],
"category": category,
}
return json.dumps(product_data)
# 塞入三萬筆資料
insert_query = "INSERT INTO product_items (product_data) VALUES (%s)"
data = [(generate_product_data(i),) for i in range(1, 30001)]
cur.executemany(insert_query, data)
conn.commit()
cur.close()
conn.close()
category = Electronics 需要的時間:26msEXPLAIN ANALYZE
SELECT
product_data ->> 'name' name,
product_data ->> 'price' price,
product_data ->> 'stock' stock
FROM
product_items
WHERE
product_data @> '{"category": "Electronics"}';
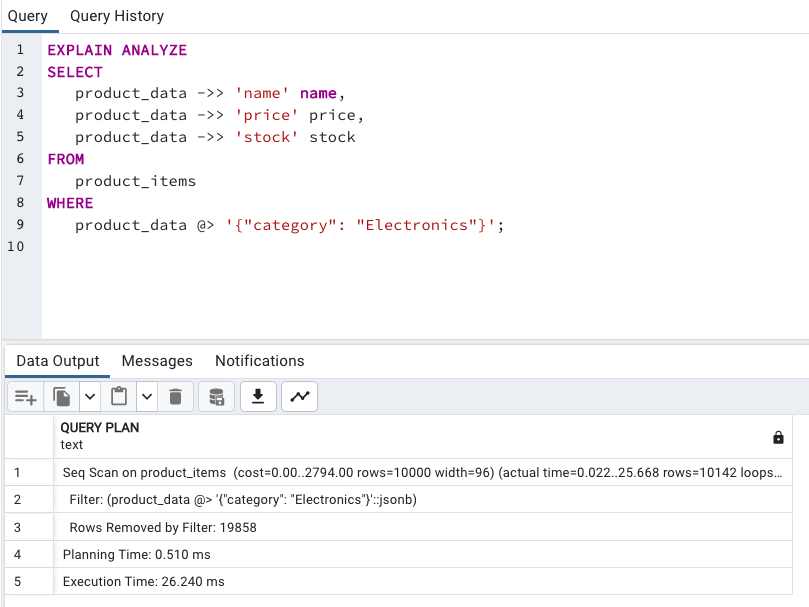
product_data 加上 GIN IndexCREATE INDEX product_data_json_index
ON product_items
USING GIN(product_data);
EXPLAIN ANALYZE
SELECT
product_data ->> 'name' name,
product_data ->> 'price' price,
product_data ->> 'stock' stock
FROM
product_items
WHERE
product_data @> '{"category": "Electronics"}';
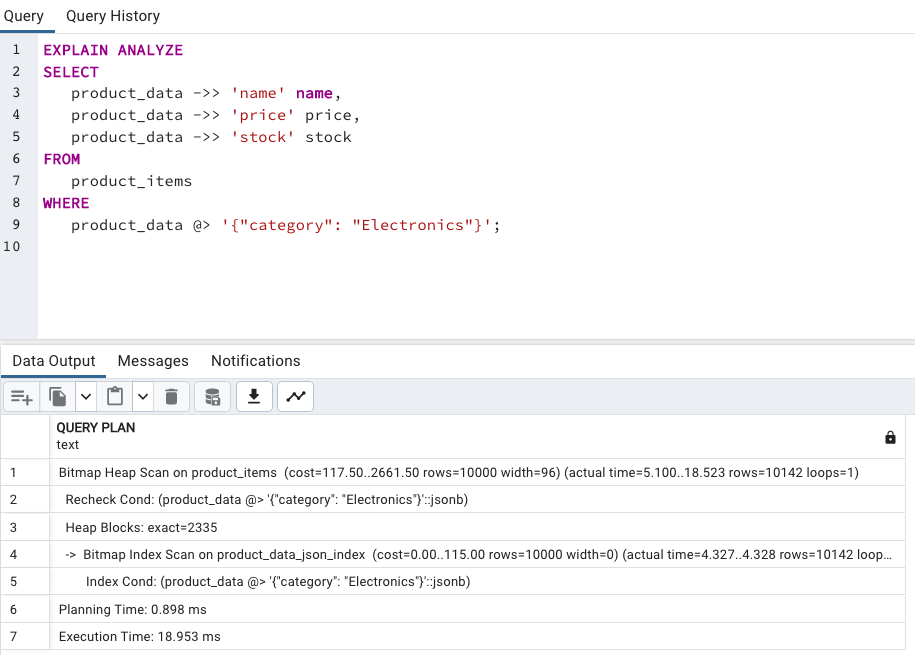
在三萬筆的情況下,從原本 26ms 變成 18ms 了。
在剛剛建立 GIN Index 的語法中,其實可以在欄位後面指定 operator class。如果搜尋時使用的是只有像 JSONB operator (@>, @?, @@)的操作,在後面指定 operator class 為 jsonb_path_ops 可以讓搜尋更快速。
Although the jsonb_path_ops operator class supports only queries with the @>, @? and @@ operators, it has notable performance advantages over the default operator class jsonb_ops.
從官方文件的敘述可以看到,剛剛我們沒有指定 jsonb_path_ops ,那麼預設的 operator 為 jsonb_ops 。只有在文件說的 @>, @?, @@ 的操作,指定為 jsonb_path_ops 才會加速查詢喔。
jsonb_path_ops:DROP INDEX product_data_json_index;
CREATE INDEX product_data_json_index
ON product_items
USING GIN(product_data jsonb_path_ops); -- 指定 jsonb_path_ops
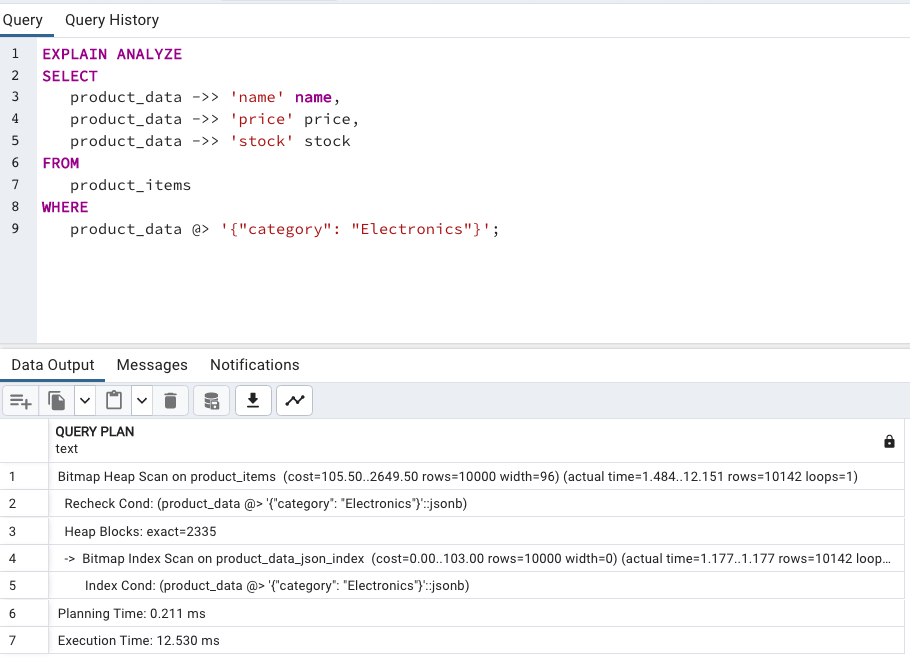
jsonb_path_ops 就沒辦法使用了,會變回 Seq Scan。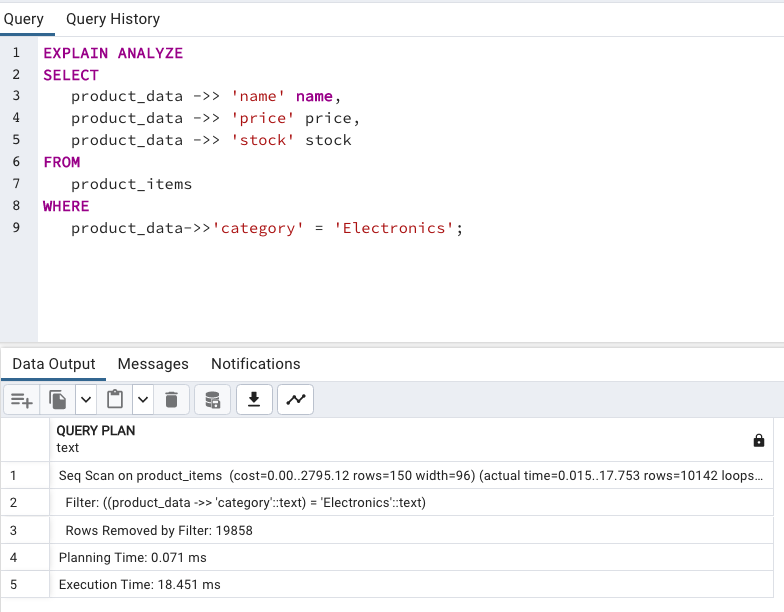
@>, @?, @@)對於 jsonb 不太熟悉的話,這裡快速列出剛剛提到可以用 jsonb_path_ops 加快查詢的三個運算子,分別代表什麼意思。其他的運算子的使用方式,官方文件上面有都有舉例說明。
1. @> :確認是否有包含
左邊的 jsonb 是否包含右邊的 jsonb(結構與值都要符合)。
範例:左邊的 {"a":1, "b":2} 使否有包含 {"b":2} ?有,所以回傳 true。
SELECT '{"a":1, "b":2}'::jsonb @> '{"b":2}'::jsonb; -- true
2. @? — JSONPath 有沒有符合條件的資料
用 JSONPath 語法檢查 JSON 是否符合條件,結果是布林值(true/false)。
範例: 在 a 裡面,有符合 > 2 這個條件的元件?有,所以回傳 true。
($.a[*] ? (@ > 2) 問號後面可以想成是過濾器條件)
SELECT '{"a":[1,2,3,4,5]}'::jsonb @? '$.a[*] ? (@ > 2)'; -- true
3. @@ — JSONPath 條件是否成立
用 JSONPath 語法直接做條件判斷,並回傳布林值(true/false)。
範例: 「a 裡面有包含 > 2 的元件」這個敘述是否成立?是,所以回傳 true。
SELECT '{"a":[1,2,3,4,5]}'::jsonb @@ '$.a[*] > 2' ; -- true
不過看到這裡,我們好像還沒有提到 GIN 使用的資料結構是什麼。明天我們會一起看 GIN 和 GiST 這兩個可以用在全文搜尋的 Index,他們的資料結構是什麼樣子。
jsonb_path_ops 操作類別可以進一步加速查詢,特別是在只使用 @>, @?, 和 @@ 等操作符時。https://www.postgresql.org/docs/current/datatype-json.html#JSON-INDEXING
